사용자의 정보는 세션 저장소에 저장되고, 쿠키는 그 저장소를 통과할 수 있는 출입증 역할을 합니다. 따라서 쿠키가 담긴 HTTP 요청이 도중에 노출되더라도 쿠키 자체에는 유의미한 값을 갖고있지 않아서 쿠키에 사용자 정보를 담아 인증을 거치는 것 보다 안전합니다.
각 각의 사용자는 고유의 Session ID를 발급 받기 때문에 일일이 회원 정보를 확인할 필요가 없어 서버 자원에 접근하기 용이합니다.
단점
쿠키에 사용자 정보를 담아 인증을 거치는 것 보다 안전하지만, 해커가 쿠키를 탈취한 후 그 쿠키를 이용해 HTTP 요청을 보내면 서버는 사용자로 오인해 정보를 전달하게 됩니다. 이를 세션 하이재킹 공격이라고 합니다. 해결책으로는 HTTPS 프로토콜 사용과 세션에 만료 시간을 넣어주는 것 입니다.
서버에서 세션 저장소를 사용하기 때문에 추가적인 저장공간을 필요로 합니다.
Access Token을 이용한 인증
JWT
JWT는 JSON Web Token의 약자로 인증에 필요한 정보들을 암호화시킨 토큰을 말하며, Access Token으로 사용됩니다. JWT를 생성하기 위해서는 Header, Payload, Verify Signature 객체를 필요로 합니다.
Header
Header는 토큰의 타입을 나타내는typ과 암호화할 방식을 정하는alg로 구성되어 있습니다.
{
'alg': 'HS256',
'typ': 'JWT'
}
Payload
Payload는 토큰에 담을 정보를 포함합니다. 여기서 하나의 정보 조각을 클레임으로 부릅니다. 클레임의 종류로는 Registered, Public, Private로 3가지가 존재합니다. 보통 만료 일시, 발급 일시, 발급자, 권한정보 등을 포함합니다.
Header, Payload는 인코딩될 뿐, 따로 암호화되지 않습니다. 따라서 Header, Payload는 누구나 디코딩하여 확인할 수 있기에 정보가 쉽게 노출될 수 있습니다. 하지만 Verify Signature는 SECRET KEY를 알지 못하면 복호화할 수 없습니다.
만약에 해커가 사용자의 토큰을 훔쳐 Payload의 데이터를 변경하여 토큰을 서버로 보낸다면, 서버에서 Verify Signature을 검사하게 됩니다. 여기서 Verify Signature는 해커의 정보가 아닌 사용자의 정보를 기반으로 암호화되었기 때문에 해커가 변경한 정보로 보낸 토큰은 유효하지 않은 토큰으로 간주합니다. 이를 통해 사용자의 SECRET KEY를 알지 못하면 토큰을 조작할 수 없다는 것을 알 수 있습니다.
인증 순서
사용자가 로그인을 합니다.
서버에서는 계정 정보를 읽어 사용자를 확인 후, 사용자의 고유한 ID값을 부여하고 Payload에 정보를 넣습니다.
사용자는 Access Token을 받아 저장한 후, 인증이 필요한 요청마다 토큰을 HTTP 요청 헤더에 실어 보냅니다.
서버에서는 해당 토큰의 Verify Signature를 SECRET KEY로 복호화한 후, 조작 여부, 유효 기간을 확인합니다.
검증이 완료된다면, Payload를 디코딩하여 사용자의 ID에 맞는 데이터를 가져옵니다.
장점
간편합니다. 세션과 쿠키를 이용한 인증은 별도의 세션 저장소의 관리가 필요합니다. 그러나 JWT는 발급 후 검증만 거치면 되기 때문에 추가 저장소가 필요없습니다.
확장성이 뛰어납니다. 토큰 기반으로 하는 다른 인증 시스템에 접근이 가능합니다.
단점
JWT는 한 번 발급되면 유효기간이 완료될 때까지는 계속 사용이 가능하며 중간에 삭제가 불가능합니다. 따라서 해커에 의해 정보가 털린다면 대처할 방법이 없습니다. 해결책으로는 Refresh Token을 추가적으로 발급하여 해결하는 방식으로 아래에서 설명하겠습니다.
Payload 정보가 디코딩하면 누구나 접근할 수 있기에 중요한 정보들을 보관할 수 없습니다.
JWT의 길이가 길기 때문에, 인증 요청이 많아지면 서버의 자원낭비가 발생합니다.
Access Token + Refresh Token을 이용한 인증
Access Token을 이용한 인증 방식의 문제는 해커에게 탈취당할 경우 보안에 취약하다는 점입니다. 토큰의 유효기간을 짧게 하면 사용자는 로그인을 자주 해야해서 번거롭고, 길게 하면 보안이 취약해지기 때문에 이를 해결하고자 나온 것이 Refresh Token입니다.
Refresh Token은 Access Token과 같은 형태인 JWT입니다. Refresh Token은 Access Token보다 긴 유효기간을 가지고, Access Token이 만료됐을 때 새로 발급해주는 열쇠가 됩니다. 예를 들어 Refresh Token의 유효 기간이 2주, Access Token의 유효 기간이 1시간이라고 한다면, 2주 동안 Access Token이 만료 되는 1시간 주기마다 Access Token을 새롭게 발급받을 수 있습니다.
인증 순서
사용자가 로그인을 합니다.
서버에서는 회원 DB에서 값을 비교합니다.
로그인이 완료되면 Access Token, Refresh Token을 발급하여 HTTP 응답 헤더에 실어 보냅니다. 이때 일반적으로 회원 DB에 Refresh Token을 저장해둡니다.
사용자는 Refresh Token은 안전한 저장소에 저장 후, Access Token을 HTTP 요청 헤더에 실어 요청을 보냅니다.
Access Token을 검증하여 이에 맞는 데이터를 보냅니다.
시간이 지나 Access Token이 만료됐다고 보겠습니다.
사용자는 이전과 동일하게 Access Token을 HTTP 요청 헤더에 실어 보냅니다.
서버는 Access Token이 만료됨을 확인하고 권한 없음을 신호로 보냅니다.
사용자는 Refresh Token과 Access Token을 HTTP 요청 헤더에 실어 보냅니다.
서버는 받은 Access Token이 조작되지 않았는지 확인한 후, HTTP 요청 헤더의 Refresh Token과 사용자의 DB에 저장되어 있던 Refresh Token을 비교합니다. Token이 동일하고 유효기간도 지나지 않았다면 새로운 Access Token을 발급해줍니다.
서버는 새로운 Access Token을 HTTP 응답 헤더에 실어 다시 API 요청을 진행합니다.
장점
Access Token의 유효 기간이 짧기 때문에, 기존의 Access Token만을 이용한 인증보다 안전합니다.
단점
구현이 복잡합니다.
Access Token이 만료될 때마다 새롭게 발급하는 과정에서 서버의 자원 낭비가 생깁니다.
OAuth 2.0을 이용한 인증
OAuth
OAuth는 외부서비스의 인증 및 권한부여를 관리하는 범용적인 프로토콜입니다.
OAuth 2.0
현재 범용적으로 사용되고 있는 것은 OAuth 2.0입니다. 2007년에 OAuth 1.0의 초안이 발표되었는데, 네트워크 시장이 커감에 따라 한계가 나타나기 시작했습니다. 그리고 2012년에 OAuth 2.0를 발표하면서 현재까지 사용되고 있습니다. 바뀐 점은 크게 3가지 입니다.
모바일에서도 사용이 용이합니다.
반드시 HTTPS를 사용하므로 보안이 강화됐습니다.
Access Token의 만료 기간이 생겼습니다.
OAuth 2.0의 인증 방식은 4가지가 있지만, 가장 범용적으로 쓰이는 Authorization Code Grant에 대해 알아보겠습니다.
인증 순서
Resource Owner: 일반 사용자
Client: 우리가 만든 웹 어플리케이션
Authorization Server: 권한 관리 및 Access Token, Refresh Token을 발급해주는 서버
Resource Server: OAuth 2.0을 관리하는 서버의 자원을 관리하는 곳
Resource Owner가 Client에게 인증 요청을 합니다.
Client는 Authorization Request를 통해 Resource Owner에게 인증할 수단(Facebook, Google 로그인 url)을 보냅니다.
Resource Owner는 해당 Request를 통해 인증을 진행하고 인증을 완료했다는 신호로 Authorization Grant를 url에 실어 Client에게 보냅니다.
Client는 해당 권한 증서를 Authorization Server에 보냅니다.
Authorization Server는 권한 증서를 확인 후, 유저가 맞다면 Client에게 Access Token, Refresh Token, 그리고 유저의 정보를 발급해줍니다.
Client는 해당 Access Token을 DB에 저장하거나 Resource Owner에게 넘깁니다.
Resource Owner가 Resource Server에 자원이 필요하면, Client는 Access Token을 담아 Resource Server에 요청합니다.
Resource Server는 Access Token이 유효한 지 확인 후, Client에게 자원을 보냅니다.
만일 Access Token이 만료됐거나 위조되었다면, Client는 Authorization Server에 Refresh Token을 보내 Access Token을 재발급 받습니다.
그 후 다시 Resource Server에 자원을 요청합니다.
만일 Refresh token도 만료되었을 경우, Resource Owner는 새로운 Authorization Grant를 Client에게 넘겨야합니다.
SNS 로그인
인증 순서
사용자가 서버에게 로그인을 요청합니다.
서버는 사용자에게 특정 쿼리들을 붙인 페이스북 로그인 URL을 사용자에게 보냅니다.
사용자는 해당 URL로 접근하여 로그인을 진행한 후 권한 증서를 담아 서버에게 보냅니다.
서버는 해당 권한 증서를 Facebook의 Authorization Server로 요청합니다.
서버는 권한 증서를 확인 후, Access Token, Refresh Token, 유저의 정보를 돌려줍니다.
받은 고유 ID를 Key값으로 해서 DB에 유저가 있다면 로그인, 없다면 회원가입을 진행합니다.
로그인이 완료되었다면 세션과 쿠키 , 토큰 기반 인증 방식을 통해 사용자의 인증을 처리합니다.
참고 사항
우리가 만들 서버에서 OAuth를 이용하기 위해서는 사전에 OAuth에 등록하는 과정이 필요합니다. 개발자 사이트에서 웹 어플리케이션을 등록 후 APP_ID와 CLIENT_ID 등을 보내야 OAuth 에서는 어느 서비스인지를 알 수 있습니다.
페이스북 로그인을 인증을 이용하는 경우, 대부분은 Resource Server(페이스북 자체 API)를 사용하지 않습니다. 따라서 Access Token, Refresh Token은 실제로 쓰이지 않습니다. 우리의 서버에서 Access token을 검증할 수도 없을 뿐더러 인증의 수단으로 활용하기엔 부족한 점이 많습니다. 따라서 보통 Authorization Server로 부터 얻는 고유 ID값을 활용해서 DB에 회원관리를 진행합니다.
JS 엔트리포인트를 지정하는게 아니라 어플리케이션 진입을 위한 HTML 파일 자체를 읽기 때문에 별도 설정 없이도 동작합니다. (Zero Config 번들러 입니다.)
HTML 파일을 순서대로 읽어가면서 JS, CSS, Asset을 직접 참조합니다.
트렌스파일러 설정이 간편합니다. JS 파일만 읽을 수 있는 일반적인 번들러와 달리 CSS, Asset 을 직접 참조하기 때문에 트렌스파일이 필요한 파일 유형을 일일이 설정해줄 필요 없이.bablerc, .postcssrc, .posthtml같은 설정 파일들을 루트 디렉토리에 만들기만 하면 자동으로 파일을 읽어와서 세팅 해줍니다.
모든 모듈에서 Babel을 사용하여 최신 JS를 브라우저에 지원하는 형식으로 컴파일합니다.
트리 쉐이킹에 강점이 있습니다. ES6, CommonJS 모듈 모두에 대해 트리 쉐이킹 지원합니다.
문제점
웹팩, 롤업에 비해 좁은 생태계, 안정성이 떨어집니다.
일반적인 케이스만 다루고 커스텀한 설정이 필요하면 결국 설정 파일을 다시 작성해야 합니다.
2012년 Tobias Koppers에 의해 webpack v1.0이 효율적으로 js파일을 통합해주는 도구로 공개되었습니다. 2016년 webpack v2.0이 릴리즈되고 ES6를 지원하여 커뮤니티의 큰 관심을 얻게 되었습니다. 2017년 webpack v3.0이 릴리즈되고 성능 개선, 기능 추가 되면서 사람들이 열광하기 시작했습니다. 2018년 webpack v4.0이 릴리즈되었는데 동시에 React, Anglular의 등장으로 SPA가 급부상하게 되면서 번들러의 역할 더욱 막중해지자 이른바 "대웹팩시대"가 도래하게 되었습니다. 현재는 2020-10-10에 릴리즈된 v5에서 지속적으로 업데이트되고 있습니다.
webpack의 정체성은 번들러의 목적인 "통합"에 있습니다. '번들을 통합해서 관리할 순 없을까?'에 대한 고민이 webpack이 부상할 수밖에 없게 만들어 주었죠.
설정이 간편하고 직관적. 하나의 설정 파일에서 원하는 번들이 생성 될 수 있도록 컨트롤할 수 있습니다. entry와 output을 명시하고 어떤 plugin과 loader로 파일들을 다룰 건지 명시하면 됩니다.
풍부한 plugins과 loaders. webpack은 굉장히 강력한 개발 커뮤니티가 뒷바침해주고 있습니다. 쉽게 plugin과 loader를 부착할 수 있기 때문인데요. loader를 통해서 파일들을 변환, 번들링, 빌드를 진행하고 plugin을 통해서 output 파일을 튜닝해줍니다.
강력한 개발서버. webpack은 Hot Module Replacement(HMR)를 처음으로 제안했고 2012년부터 사용되어왔습니다. HMR는 소스코드의 변화를 감지하여 브라우저를 직접 새로고침할 필요가 없이 변화를 바로 반영해줍니다. 개발자는 덕분에 더욱 신속하게 개발할 수가 있게 되었죠. webpack v2, v3, v4을 거쳐서 다양한 파일(css)의 변화도 감지할 수 있게 되었고 안정화되었습니다.
"Code splitting is one of the most compelling features of webpack."
한마디로 설명하자면 번들 로드 최적화하는 작업입니다. 파일들을 여러 번들 파일으로 분리하여 병렬로 스크립트를 로드하여 페이지 로딩속도를 개선할 수 있습니다. 추가로 초기에 구동될 필요가 없는 코드를 분리하여 lazy loading을 통해 페이지 초기 로딩속도를 개선할 수 있습니다.
끝으로 당시 같이 거론되었던 번들링 라이브러리에 대해서 비교하면서 webpack 설명을 마치겠습니다.
vs grunt
grunt는 task runner입니다. minifying, 파일 통합, lint 적용 등 등록된 task를 순서대로 실행시켜 줍니다. 설정이 파편화되고 개발자가 직접 컨트롤해야하는 영역이 많습니다. 반면 webpack은 module bundler로 모듈을 통합하는 것에 초첨이 맞춰져 있습니다.
vs glup
glup은 grunt와 흡사한 task runner입니다. 다만 stream-based로 파일을 접근하기에 grunt에 비해 성능이 더 우수하다고 평가를 받고 있습니다.
Rollup
webpack 시대 개막과 함께 2017년부터 개발이 시작된 module bundler입니다. 대세적으론 webpack의 열풍에 가려져 있었지만 점차 그의 매력이 인정을 받아 많은 차세대 번들러가 rollup을 벤치마킹하게 되었습니다.
"compiles small pieces of code into something larger and more complex, such as a library or application"
작은 코드조각들을 거대하고 복잡한 어플리케이션 혹은 라이브러리로 만들어 준다고 스스로 소개합니다. 같은 소스코드를 다양한 환경에 맞춰 다르게 발드하는 것을 생각하면 될 것 같습니다. 그러면서 자연스럽게 아래 여론이 형성되었습니다.
"어플리케이션 만들 땐 webpack으로, 라이브러리 만들 땐 rollup으로!"
rollup의 사용방식과 구성방식은 webpack과 거의 흡사합니다. input과 entry를 설정하고 번들링에 적용할 기능을 plugin 형태로 끼워 넣으면 됩니다.
import commonjs from '@rollup/plugin-commonjs';
import resolve from '@rollup/plugin-node-resolve';
import { terser } from 'rollup-plugin-terser';
const production = !process.env.ROLLUP_WATCH;
export default {
input: 'src/main.js',
output: {
file: 'public/bundle.js',
format: 'iife',
sourcemap: true,
},
plugins: [
resolve(),
commonjs(),
production && terser(),
],
};
webpack과의 차이를 비교해보면 더 정확하게 rollup의 특성을 이해할 수 있습니다.
vs webpack
한마디로 정리하면, webpack은 내부적으로 Commonjs를 사용하고 rollup은 typescript(ES6)를 사용합니다. 이로 인해서 아래 특성들이 있다고 볼 수 있습니다.
rollup은 ES6 모듈 형태로 빌드할 수 있습니다. webpack은 CommonJS 형태로만 번들링이 가능했습니다. 물론 webpack v5부턴 ES6로 번들할 수 있습니다. 라이브러리는 ES6 번들에 생성에 대한 수요가 강합니다. ES6 환경에서는 ES6 번들이 사용되고 CommonJS 환경에서는 CommonJS 번들이 사용되도록 해줘야 라이브러리 사용자는 더욱 최적화된 애플리케이션을 빌드해줄 수 있습니다.
rollup은 좀 더 빠릅니다. webpack은 모듈들을 함수로 감싸서 평가하는 방식을 사용하지만 rollup은 모듈들을 호이스팅하여 한번에 평가하기에 성능상 이점이 있습니다.
rollup은 더 가벼운 번들을 생성합니다 tree shaking은 기본적으로 ES6 코드에서 제대로 동작합니다. 단순히 레퍼런스되지 않는 코드를 제거하는 것이 아닌 사용되는 모듈만 AST 트리에 포함시키는 방식으로 불필요한 코드를 제거하기 때문입니다. rollup은 공식 플로그인을 통해서 CommonJS 코드를 ES6 코드로 변환할 수도 있습니다.
rollup은 CommonJS 코드를 ES6코드에서 사용할 수 있습니다. 기본적으로 ES6에서는 CommonJS식의 require를 지원하지 않습니다. webpack에서도 공식적으론 ES6 혹은 CommonJS 한 형태의 코드 베이스를 사용하기를 권장합니다.
ESBuild
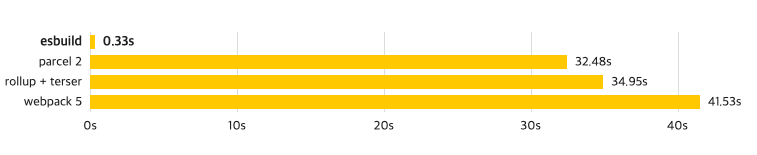
앞서 봐왔던 번들러는 모두 내부적으로 JavaScript을 기반으로 번들링을 합니다. 따라서 JavaScript 언어가 가질 수 밖에 없는 성능상의 한계가 있습니다. 그 한계를 뿌수고자하는 움직임이 있었으니 그 라이브러리가 바로 ESBuild 입니다.
ESBuild는 내부적으로 Go로 작성되었고 JS 기반의 번들러보다 10배에서 100배까지 빠른 엄청난 퍼포먼스를 보여줬습니다. 빠른 이유에 대해서는 아래와 같이 소개하고 있습니다.
브라우저에서 ESM(ES Modules)을 지원하기 전까지, JavaScript 모듈화를 네이티브 레벨에서 진행할 수 없었습니다. 그래서 소스 모듈을 브라우저에서 실행할 수 있는 파일로 크롤링, 처리 및 연결하는 "번들링(Bundling)"이라는 해결 방법을 사용해야 했습니다.
Webpack,Rollup그리고Parcel과 같은 도구는 이런 번들링 작업을 진행해줌으로써 프런트엔드 개발자의 생산성을 크게 향상시켰습니다.
하지만 애플리케이션이 점점 더 발전함에 따라 처리해야 하는 JavaScript 모듈의 개수도 극적으로 증가하고 있습니다. 심지어 수천 개의 모듈이 존재하는 것도 대규모 프로젝트에서는 그리 드문 일이 아닙니다. 이러한 상황에서 JavaScript 기반의 도구는 성능 병목 현상이 발생되었고, 종종 개발 서버를 가동하는 데 비합리적으로 오랜 시간을 기다려야 한다거나 HMR을 사용하더라도 변경된 파일이 적용될 때 까지 수 초 이상 소요되곤 했습니다. 이와 같은 느린 피드백 루프는 개발자의 생산성과 행복에 적지 않은 영향을 줄 수 있습니다.
Vite는 이러한 것에 초점을 맞춰, 브라우저에서 지원하는 ES Modules(ESM) 및 네이티브 언어로 작성된 JavaScript 도구 등을 활용해 문제를 해결하고자 합니다.
콜드 스타트 방식으로 개발 서버를 구동할 때, 번들러 기반의 도구의 경우 애플리케이션 내 모든 소스 코드에 대해 크롤링 및 빌드 작업을 마쳐야지만이 실제 페이지를 제공할 수 있습니다. (콜드 스타트는 최초로 실행되어 이전에 캐싱한 데이터가 없는 경우를 의미합니다. - 옮긴이)
vite는 애플리케이션의 모듈을dependencies와source code두 가지 카테고리로 나누어 개발 서버의 시작 시간을 개선합니다.
Dependencies: 개발 시 그 내용이 바뀌지 않을 일반적인(Plain) JavaScript 소스 코드입니다. 기존 번들러로는 컴포넌트 라이브러리와 같이 몇 백 개의 JavaScript 모듈을 갖고 있는 매우 큰 디펜던시에 대한 번들링 과정이 매우 비효율적이었고 많은 시간을 필요로 했습니다.
Vite의사전 번들링기능은Esbuild를 사용하고 있습니다. Go로 작성된 Esbuild는 Webpack, Parcel과 같은 기존의 번들러 대비 10-100배 빠른 속도를 제공합니다.
Source code: JSX, CSS 또는 Vue/Svelte 컴포넌트와 같이 컴파일링이 필요하고, 수정 또한 매우 잦은 Non-plain JavaScript 소스 코드는 어떻게 할까요? (물론 이들 역시 특정 시점에서 모두 불러올 필요는 없습니다.)
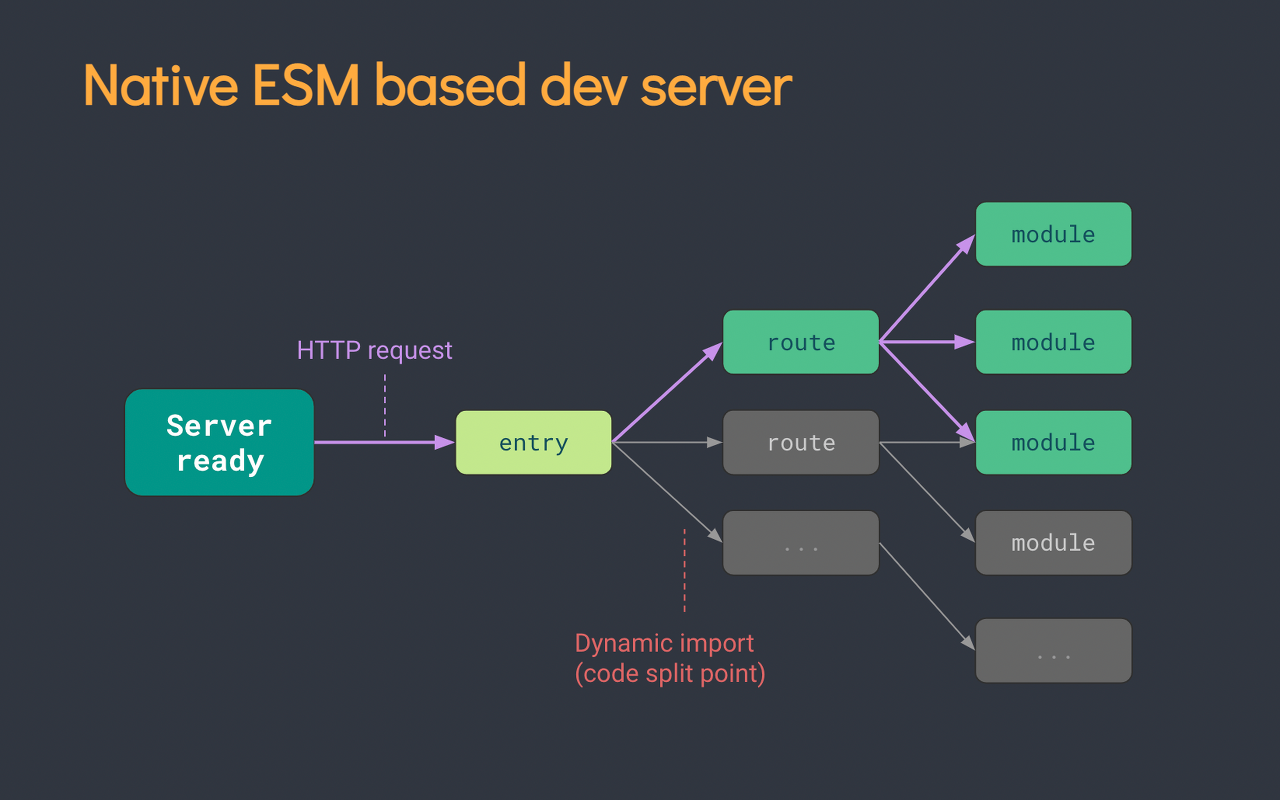
vite는Native ESM을 이용해 소스 코드를 제공합니다. 이것은 본질적으로 브라우저가 번들러의 작업의 일부를 차지할 수 있도록 합니다. vite는 브라우저가 요청하는 대로 소스 코드를 변환하고 제공하기만 하면 됩니다. 조건부 동적 import 이후의 코드는 현재 화면에서 실제로 사용되는 경우에만 처리됩니다.
Bundle based dev serverentry···routeroutemodulemodulemodulemodule···BundleServer readyNative ESM based dev serverentry···routeroutemodulemodulemodulemodule···Server readyDynamic import (code split point)HTTP request
기존의 번들러 기반으로 개발을 진행할 때, 소스 코드를 업데이트 하게 되면 번들링 과정을 다시 거쳐야 했었습니다. 따라서 서비스가 커질수록 소스 코드 갱신 시간 또한 선형적으로 증가하게 됩니다.
일부 번들러는 메모리에서 작업을 수행하여 실제로 갱신에 영향을 받는 파일들만을 새롭게 번들링하도록 했지만, 결국 처음에는 모든 파일에 대한 번들링을 수행해야 했습니다. "모든 파일"을 번들링 하고, 이를 다시 웹 페이지에서 불러오는 것이 얼마나 비효율적인 것인지 느껴지시나요? 이러한 이슈를 우회하고자 HMR(Hot Module Replacement) 이라는 대안이 나왔으나, 이 역시 명확한 해답은 아니었습니다.
물론, vite는 HMR을 지원합니다. 이는 번들러가 아닌 ESM을 이용하는 것입니다. 어떤 모듈이 수정되면 vite는 그저 수정된 모듈과 관련된 부분만을 교체할 뿐이고, 브라우저에서 해당 모듈을 요청하면 교체된 모듈을 전달할 뿐입니다. 전 과정에서 완벽하게 ESM을 이용하기에, 앱 사이즈가 커져도 HMR을 포함한 갱신 시간에는 영향을 끼치지 않습니다.
또한 vite는 HTTP 헤더를 활용하여 전체 페이지의 로드 속도를 높입니다. 필요에 따라 소스 코드는304 Not Modified로, 디펜던시는Cache-Control: max-age=31536000,immutable을 이용해 캐시됩니다. 이렇게 함으로써 요청 횟수를 최소화하여 페이지 로딩을 빠르게 만들어 줍니다.
이제 기본적으로 ESM이 대부분의 환경에서 지원되지만, 프로덕션에서 번들 되지 않은 ESM을 가져오는 것은 중첩된 import로 인한 추가 네트워크 통신으로 인해 여전히 비효율적입니다(HTTP/2를 사용하더라도). 프로덕션 환경에서 최적의 로딩 성능을 얻으려면 트리 셰이킹, 지연 로딩 및 청크 파일 분할(더 나은 캐싱을 위해)을 이용하여 번들링 하는 것이 더 좋습니다.
개발 서버와 프로덕션 빌드 간에 최적의 출력과 동작 일관성을 보장하는 것은 쉽지 않습니다. 이것이 바로 Vite가 미리 설정된빌드 커맨드를 이용하고,빌드 퍼포먼스 최적화를 진행하는 이유입니다.
Webpack vs vite
실제로 웹팩과 비교해서 vite 가 얼마나 빌드시간이 빠른지 React - TypeScript 보일러 플레이트를 생성하여 비교해보았습니다.
build time
vite (1.40s) < webpack (2.83s)
dev-server ready time
vite (1.81s) < webpack (7.80s)
완벽히 같은 파일로 컴파일 해본 건 아니지만 vite 서버의 빌드 타임과 dev server ready time 이 훨씬 더 빠른 것으로 알 수 있습니다.
왜 빠를까?
우선 dev server 시작 시간이 빠른 이유는 esbulid를 이용하여 종속성을 미리 묶기 때문입니다. esbulid는 Go 언어로 작성된 매우 빠른 번들러로, Go 언어의 특화된 병렬처리로 빠르게 번들링 해줍니다.
Vite는 기본 ESM 을 통해 소스 코드를 제공합니다 . 이것은 본질적으로 브라우저가 번들러 작업의 일부를 인계받게 하는 것입니다. Vite는 브라우저가 요청할 때 요청에 따라 소스 코드를 변환하고 제공하기만 하면 됩니다. 조건부 동적 가져오기 뒤에 있는 코드는 현재 화면에서 실제로 사용되는 경우에만 처리됩니다.
그러나, 프로덕션 빌드에서는 esbulid를 사용하지 않고 있다고 합니다. (아직 esbuild가 1버젼이 넘지 않았고 용량이 큰 프로덕션 버젼에서 필요한 트리쉐이킹이나 코드스플리팅과 같은 최적화 기능을 제공하지 않기 때문입니다.) 대신, 당분간 이런 측면에서 보다 유연한 Rollup을 이용하여 번들링하고 있습니다.
Rollup 또한 역시 Webpack 보다는 번들링 속도가 빠릅니다.
롤업의 작동방식은 모든 모듈을 함수로 랩핑하는 webpack 과는 다르게 코드들을 동일한 수준으로 올리고 한번에 번들링을 진행하기 때문에 빠릅니다. 롤업에서 식별자 충돌을 상황에 따라 식별자를 변경해 방지하고 있습니다.
At its core, webpack is a static module bundler for modern JavaScript applications. When webpack processes your application, it internally builds a dependency graph from one or more entry points and then combines every module your project needs into one or more bundles, which are static assets to serve your content from. Webpack Concepts
html에 들어가는다수의 js 파일들을 하나의 js 파일로만들어 주는 것을 의미한다.
js 파일 뿐만 아니라 css, image, html 등을 모듈로 로드해서 사용할 수 있고 코드를 압축하는 기능을 제공하며 번들링 된 파일이 너무 무거워질 경우, 다시 여러 개의 파일로코드 스플리팅(Code Spliting) 할 수 있다.
여기서 말하는 모듈(module)이란?
관련된 데이터와 함수들이 묶여 module을 형성하고 주로 파일 단위로 관리된다. 모달은 isShow라는 상태와 show, close 함수를 가진 하나의 모듈이라고 할 수 있다.
모듈들은 각각의 javascript 파일에서 관리된다.
여기서 말하는 번들러(bundler)란?
모듈별로 나누어진 파일을 연관되어 있는 단위로 묶어 하나의 파일로 만들어주는 역할을 한다. (모듈 또는 외부 라이브러리 간의 의존성을 쉽게 관리할 수 있다.) 🧐 alert, confirm, propmt라는 모듈이 있을 때, 이들을 대화상자라는 하나의 번들로 묶을 수 있다. alert이 a 라이브러리를 사용하고 있다면 a 라이브러리도 함께 번들링 된다.
웹 페이지에서 모듈을 사용하려면 해당 모듈과 모듈에서 사용하는 라이브러리를 로드해야 하는데 선후 관계를 따져 순서대로 로드해야 한다. 모듈의 수가 얼마 되지 않는다면 간단하게 로드할 수 있지만 수가 많아지면 매우 복잡해진다. 또한 이렇게 많은 양의 파일을 로드한다면 네트워크 병목현상이 발생할 수 있다. 하나의 자바스크립트 파일 안에 많은 양을 작성하면 해결할 수 있지만 이럴 경우 가독성도 떨어지고 유지보수도 힘들어진다. 이때, 번들링 된 파일을 로드하면 문제를 해결할 수 있다. 모듈을 번들링 하는 과정 중, 모듈이나 외부 라이브러리의 의존성들을 로드하기 때문에 선후 관계를 따질 필요가 없으며, 여러 파일로 작성된 모듈들을 연관된 특정 단위로 묶어서 하나의 파일로 만들기 때문에 병목현상도 예방할 수 있다.
웹팩은 프로젝트에 필요한 모든 모듈을 매핑하고 하나 이상의 번들을 생성하는 디펜던시 그래프를 생성한다.
Entry 엔트리 포인트는 웹팩이 내부의 디펜던시 그래프를 생성하기 위해 사용하는 모듈이다. 즉, 엔트리 포인트는 웹팩이 번들링을 시작할 메인 파일이다.엔트리 포인트는 꼭 하나가 아니라 여러 엔트리 포인트를 지정할 수 있는데 이때 이름(name)과 콘텐츠 해시(contentHash) 가진 여러 개의 번들로 만들 수 있다.
Output output 속성은 생성된 번들을 내보낼 위치와 파일의 이름을 지정하는 역할을 한다. publicPath 옵션 다른 도메인이나 CDN에서 일부 또는 모든 출력 파일을 호스팅 하려는 경우 사용할 수 있으며 Webpack Dev Server에서는 출력 파일의 URL 경로로 사용된다.
// webpack.config.js module.exports ={ output:{ path: path.resolve(__dirname,'dist'),// 내보낼 위치 filename:'my-first-webpack.bundle.js',// 생성된 번들 파일 이름},};
Loaders 웹팩은 자바스크립트와 JSON 파일만 이해한다. 만약 JSX 같은 코드를 이해하기 원한다면 로더를 사용하여 해당 코드들을 웹팩이 이해할 수 있도록 변환할 로더를 옵션으로 설정하고 그것들을 디펜던시 그래프에 추가할 수있는 유효한 모듈로 변환한다.
test: 변환이 필요한 파일들을 식별한다.
use: 변환을 수행하는 데 사용되는 로더를 가리킨다. babel-loader를 사용하면 최신 문법으로 작성된 Javascript를 모든 브라우저에서 해석할 수 있도록 변환할 수 있다.
Plugins 로더는 특정 유형의 모듈(JSX 파일 같은)을 변환하는 데 사용하지만 플러그인은 번들을 최적화하거나 asset을 관리하고 환경 변수 주입 등과 같은 작업을 수행한다. Webpack 패키지에 포함된 내장 플러그인 외에 추가로 필요한 기능은 외부 플러그인을 받아서 사용할 수 있다.HtmlWebpackPlugin은 HTML 파일을 생성하고 자동으로 생성된 모든 번들을 삽입한다.
Vite:하나의 파일에 모든 종속 모듈을 전역 범위로 선언하여 결합합니다. 중복을 제거하기 때문에 가볍고 빠르게 빌드할 수 있습니다.
그렇다면 Webpack을 Vite로 교체해야 할까요?
Vite는 번들링 속도에서 강점이 있지만,마이그레이션과 안정성 측면에서의 문제가 거론되고 있습니다.
Vite는개발 환경에서 esbuild를 사용하지만프로덕션 환경에서는 Rollup으로 번들링을 수행합니다. 따라서 Webpack에서 Vite로 마이그레이션을 한다면 Rollup config를 설정하는 것에 많은 시간을 투자해야합니다.
Rollup 설정에는 CommonJS 처리, Polyfill 처리 등이 되어있지 않기 때문에 일일이 플러그인을 설치해야해서 번거롭습니다. 하지만 설정을 마치게 되면 정작 프로덕션 환경에서는 Webpack과 빌드 시간에서 차이가 크게 나지 않는다고 합니다.
게다가개발 환경과 프로덕션 환경의 설정이 다르기 때문에 빌드 안정성이 낮아서개발 환경에서만 사용한다는 의견도 많습니다.
저 또한 프로덕션 환경에서는 안정성이 매우 중요하다고 생각하기 때문에개발 또는 테스트 환경에서는 Vite를 사용하여 속도를 높이고,프로덕션에서는 Webpack으로 빌드 안정성을 확보하는 것이 좋다고 생각합니다.
글을 마치며
지금까지 모듈 번들러의 사용 이유와 대표적인 번들링 툴인 Webpack에 대해서 알아보았습니다. 그리고 최근 높은 번들링 속도로 주목을 받고 있는 Vite와 Webpack의 차이점에 대해서 알아보면서 Webpack을 교체하는 것이 필요한 지에 대해서 생각해보기도 했습니다.
환경과 목적에 맞는 번들링 도구를 선택할 수 있도록 이번 글이 도움이 되었으면 좋겠습니다.
JavaScript 프레임워크인 React, Vue, Svelte, Angular 등을 사용하다 보면 모듈 번들러(module bundler)는 필수적으로 언급되는 내용입니다. 모듈 번들러는 개념적으로 생각보다 쉬운 내용이지만 웹팩, 롤업, 파셀, 모듈, 번들러, 종속성, 로더 등 해당 용어는 무엇이고 어떻게 동작하는지 잘 모르기 때문에 대부분 이해하지 않고 넘어가게 됩니다.
하지만, FrontEnd 개발자라면 모듈 번들러의 개념과 필요성을 꼭 알아야 한다고 생각하고 개인적으로 헷갈리는 부분이 있어서 이번 포스팅에서 모듈 번들러에 대해 정리하고자 합니다.
모듈(Module)
모듈 번들러는 Module + Bundling이 혼합된 단어인데, 모듈은 '분리된 코드 조각'을 의미하고 번들링은 '묶는다'는 의미입니다. 즉, 모듈 번들러는 분리된 코드 조각을 묶는다는 의미입니다. '분리된 코드 조각'이라는 의미를 가지는 모듈에 대해 알아봅시다.
애플리케이션의 기능이 많아질수록 작성해야하는 코드가 길어질 수 있습니다. 모든 코드를 한 개의 파일에 작성하는 대신 기능(변수, 객체, 배열, 함수, 클래스 등)에 따라 별도의 파일에 코드를 분리할 수 있습니다. 코드를 분리하는 기준에 따라 파일이 상당히 많아질 수 있지만, 한 개의 파일에 코드를 작성하는 것보다 체계적이고 유지보수가 쉬워집니다.
결국 모듈은 분리된 파일을 의미합니다. JavaScript에서 현재 모듈을 다른 모듈에서 접근할 수 있도록 export 키워드를 사용하며, 분리된 모듈을 불러오기 위해 import 키워드를 사용합니다.
모듈 번들러(Module Bundler)의 필요성
React, Angular, Vue와 같은 JavaScript 프레임워크가 등장하기 전에는 웹 사이트를 구축하기 위해 HTML, CSS, JavaScript 뿐이었기 때문에 파일 관리가 복잡하지 않았습니다. 하지만, 시간이 지나면서 조금 더 나은 성능, 속도를 만족하기 위해 다양한 JavaScript 프레임워크가 등장하였으며, 웹 사이트를 구축하기 위해 필요한 파일들이 점점 많아집니다.
스벨트의 node_modules 폴더만 봐도 상당히 많은 모듈이 존재합니다. 참고로 스벨트는 다른 프레임워크에 비해 모듈이 적은 편입니다.
이렇게 많은 모듈을 하나로 묶는 과정은 쉽지 않으며, 변수 또는 함수 이름이 중복되는 경우 그리고 모듈간 종속성 때문에 배포하기 전부터 수많은 문제가 발생합니다.
모듈간 종속성이란 예를 들어 설명하자면, A.js 파일은 B.js를 import 하고 B.js 파일은 C.js 파일을 import 하고.. 이렇게 모듈끼리 서로 종속되는 것을 의미하며, 모듈 간 종속성이 복잡한 경우 어떤 모듈에서 문제가 발생했는지 추적하는 것도 쉽지 않습니다.
하나의 파일로 병합하더라도 병합하는 과정에서 발생하는 문제를 해결하는데 상당히 많은 시간을 소모하게 되므로 상당히 비효율적입니다.
모듈 번들러(module bundler)
모듈 번들러는 위에서 언급한 모든 문제를 해결하여 짧은 시간에 최상의 성능을 위해 애플리케이션을 최적화하는 개발 도구입니다. 모듈 번들러의 핵심 작업은 여러 JS 파일을 하나의 결합하여 단일 파일을 만드는 것입니다. 따라서, Chrome과 같은 브라우저는 하나의 단일 파일을 로드함으로써 애플리케이션이 동작합니다.
모듈 번들러는 JS 파일뿐만 아니라 CSS 파일과, 이미지, 글꼴 등 여러 리소스에 대해서도 번들링 됩니다. 모듈 번들러는 웹팩, 롤업처럼 다양한 개발 도구가 존재하며 번들링 동작 방식은 개발 도구마다 다릅니다.
질문중 프론트엔드가 받을만한 질문이 있냐고 하실수있지만 퍼블리셔는 UI를 만들어야하고 그렇기때문에 스크립트를 잘 알아야합니다. 특히 요새는 react,vue 퍼블이라고 하여 마크업과 ui기능동작을 만들어줄 사람을 찾기때문에 프론트 면접 질문과 겹치는 부분들이 있을수 있습니다.
웹 표준
웹 표준(Web Standards) 1. 웹 표준이란? - '웹에서 표준적으로 사용되는 기술이나 규칙' - 표준화 단체인 W3C가 권고한 표준안에 따라 웹사이트를 작성할 때 이용하는 HTML, CSS, JavaScript 등에 대한 규정이 담겨 있다. - 어떤 운영체제나 브라우저를 사용하더라도 웹페이지가 동일하게 보이고 정상 작동해야함을 의미. - 표준 스펙을 잘 지키는 것 뿐만 아니라 구조적 마크업(XHTML)과 표현 및 레이아웃(CSS) 및 사용자 행위 제어(DOMScripting)를 잘 분리하는 고급 홈페이지 구축 방식. - CSS 와 HTML(XHTML)로 웹 문서를 작성하는 것의 명확한 용어는 권고(recommend)라고 하며 버전과 상관없이 HTML, XHTML은 그 자체로 표준이라고 한다.
http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> 위의 다섯가지가 제일 많이 사용되는 것이다. DTD를 적지 않는 브라우저들은 Quirks Mode 상태(어물쩡한 상태)로 렌더링 되기 때문에 바른 DTD를 적어주는 것이 좋다. 크로스 브라우징을 하기 위해서는 꼭 필요한 원칙이다. 우리나라에서는 DOCTYPE 중에서XHTML 1.0 Transitional를 제일 많이 사용중이다. 그 이유중에 하나는 IE중에서도 하위 브라우저를 사용하는 곳이 많기 때문이다. 또 하나는 표준모드는 너무 엄격하여 적용하기가 쉽지 않아 하위 브라우저 호환성을 고려하여 느슨한 상태의 호환모드 DOCTPYE 이다. 그렇지만 IE7이상에서 사용할 때는 HTML5를 사용해도 무관하니 참고 바람.
Quirks MODE(쿼크모드) 렌더링과 DTD
쿼크모드(Quirks mode)
오래된 웹 브라우저를 위하여 디자인된 웹 페이지의 하위 호환성을 유지하기 위해 W3C나 IETF의 표준을 엄격히 준수하는 표준모드(Standards Mode)를 대신하여 쓰이는 웹 브라우저 기술을 가리킨다. 참고문헌 쿼크모드의 발생 원인
DOCTYPE 선언이 존재하지 않거나 잘못 적혀있을 경우, 웹 브라우저는 문서를 쿼크 모드로 해석한다.
DOCTYPE 선언 내의 URL이 생략된 경우, 웹 브라우저는 문서를 쿼크 모드로 해석한다.
호환 출력 방식(Quirks Rendering Mode)의 특징
브라우저가 HTML을 읽는데 시간이 더 걸린다.
브라우저가 HTML을 해석하는데 시간이 더 걸린다.
브라우저가 HTML을 출력하는데 시간이 더 걸린다.
브라우저마다 HTML을 각각 다르게 출력한다.
IE10에서 쿼크 모드를 볼 수 있다.
DTD 정의 필요성
문서의 가독성 증가
브라우저 별 호환성 증가(크로스 브라우징)
문서 제작의 효율성 증가
참고사항
HTML5가 표준이 되었지만 아직 IE 웹 브라우저에서는 호환성 보기 헤더(X-UA-Compatible header)가 설정되지 않을 경우, 쿼크모드(Quirksmode)로 변경되는 문제를 가진다.
적응형 웹 디자인을 사용하면 웹 페이지에서 감지된 기기를 기반으로 미리 만들어진 정적인 레이아웃을 불러올 수 있습니다.이러한 작업이 수행되기 위해선 디자이너가 다양한 화면 너비에 맞춰 별도로 디자인 작업을 해야 합니다. 가장 일반적인 너비는 다음과 같습니다(픽셀 단위):
해외는 100%로 작업하여 %기반의 작업이 많은 반면 국내는 브레이크 포인트의 차이로 작업하는걸 이야기하는부분이 많습니다.
그런데 요새 추세는 이러한것들이 에매한것이 테블릿과 테블릿PC가 나오며 SIZE로 구분하기 어려워졌습니다. 테블릿이 1980을 넘는것들이 나오기시작하면서 기준을 어떻게 해야하는지 기획팀과 확실히 이야기를 하는것이 좋습니다.
css 방법론
OOCSS(Object Oriented CSS)는 CSS를모듈(module) 방식으로 작성하여 중복을 줄이는 방식의 방법론이다 BEM(Block Element Modifier)은블록(block), 요소(element), 상태(modifier)로 구분하여 클래스 이름을 작성하는 방식의 방법론이다 SMACSS(Scalable and Modular Architecture for CSS)는 CSS를범주화(Categorization)로 패턴화 하고자 하는 방법론이다
요즘 사람들은 궁금한 것에 대한 답을 대부분 Google에 검색하여 답을 얻곤 하는데요. 그렇기 때문에 당연히 모든 비즈니스 및 웹사이트 소유주들은 Google에서 자신들의 정보를 사람들이 찾기 쉽도록 만들기 위해서라면 할 수 있는 모든 것을 합니다. 이것이 바로 SEO입니다. 즉, 검색 결과에서 상위에 노출될 수 있도록 내 콘텐츠를 최적화하는 방식을 말합니다.
SEO(검색 엔진 최적화)는 웹사이트가 유기적인(무료) 검색 방식을 통해 검색 엔진에서 상위에 노출될 수 있도록 최적화하는 과정을 말합니다. 비즈니스 유형이 어떤 것이든 SEO는 가장 중요한 마케팅 유형 중 하나입니다.
왜냐하면 Google은 검색하는 사람들에게 긍정적인 사용자 경험을 선사하는 것이 목표이기 때문에 가능한 한 최고의 정보를 제공하길 원합니다. 따라서, SEO 노력은 검색 엔진이 여러분의 콘텐츠를 특정 검색어에 대한 웹 상의 주요한 정보로 인식하도록 하는 과정에 포커스를 맞추어야 합니다.
<meta>태그는 HTML 문서에 대한 메타 데이터를 제공합니다. 메타 페이지에 표시되지 않지만, 기계 분석 할 것이다. 메타 엘리먼트는 일반적으로 페이지 설명, 키워드, 문서 저자, 마지막 수정, 및 다른 메타 데이터를 지정하는 데 사용된다. 메타 데이터 브라우저에서 사용할 수있는 검색 엔진 (키워드), 또는 다른 웹 서비스 (콘텐츠 또는 다시로드 페이지를 표시하는 방법).
각 옵션의 선택사항 :
Page-Enter : 페이지 들어갈 때 효과 줌
Page-Exit : 페이지 나올 때 효과 줌
blendtrans : 점점 밝게 또는 점점 어둡게 나타나도록 설정
revealtrans : 문서 전환 효과 지정
duration : 시현 시간 지정
transition=0 사각형 작아지기
transition=1 사각형 커지기
transition=2 원 작아지기
transition=3 원 커지기
transition=4 위에서 아래로
transition=5 아래이서 위로
transition=6 왼쪽에서 오른쪽
transition=7 오른쪽에서 왼쪽
transition=8 수직 블라인드
transition=9 수평 블라인드
transition=10 체크무늬 왼쪽에서 오른쪽으로
transition=11 체크무늬 위에서 아래로
transition=12 랜덤 뿌리기
transition=13 수직 2등분 가운데로 모움
transition=14 수직 2등분 바깥으로 퍼짐
transition=15 수평 2등분 가운데로 모움
transition=16 수평 2등분 바깥으로 퍼짐
transition=17 45도 오른쪽 위에서 왼쪽 아래로
transition=18 45도 오른쪽 아래에서 왼쪽위로
transition=19 -45도 왼쪽 위에서 오른쪽 아래로
transition=20 -45도 왼쪽 아래에서 오른쪽 위로
transition=21 수평 랜덤
transition=22 수직 랜덤
transition=23 1~22 랜덤 선택
로봇을 제어하는 메타태그
robot.txt 파일을 생성하지 않고 메타태그를 활용하여 로봇을 제어할 수 있습니다.
<meta name="robots" content="all" />
<!-- // 로봇 검색을 허가한다. // -->
<meta name ="robots" content="none" />
<!-- // 로봇 검색을 허가하지 않는다. // -->
<meta name="robots" content="index,follow" />
<!-- // 이 파일을 읽는다. 링크 연결 문서도 읽는다. // -->
<meta name="robots" content="noindex,follow" />
<!-- // 이 파일은 읽지 않는다. 링크 연결 문서만 읽는다. // -->
<meta name="robots" content="index,nofollow" />
<!-- // 이 파일을 읽는다. 링크 연결은 무시한다. // -->
<meta name="robots" content="noindex,nofollow" />
<!-- // 이 파일를 읽지 않는다. 링크 연결도 무시한다. // -->
px은 우리가 알고 있는 픽셀값입니다. 우리가 해상도를 지정할 때 1920x1080 로 지정한다면, width(너비)는 1920px이고, height(높이)는 1080px이라는 것입니다. 위의 예시에서 p태그 속성값에 400px을 주었다면 p태그로 묶인 문장들은 너비가 400px로 고정됩니다. 창이 400px보다 줄어들면 스크롤이 생기게 됩니다. font-size의 기본값은 16px입니다. 즉, 아무런 지정을 하지 않는다면 font-size는 16px이 기본값입니다.
%
%는 사용자가 보이는 화면에서 차지하는 비중입니다. 가령 위의 예시에서 p의 속성값이 400px가 아닌 70%라면 창이 줄어들든 늘어나든 사용자 입장에서 보이는 화면의 70%만 <p>태그가 사용하게 됩니다. 즉, 부모가 만들어준 공간안에서의 너비 비율로 볼 수 있습니다. 가령, 위 예시에서 p의 속성값이 70%라면, p의 부모는 body이므로, body(부모)가 만들어준 공간 안에서의 70%로 볼 수 있습니다. body자체에 margin값(여백)이 살짝 존재하므로 화면에 살짝 여백이 존재합니다. margin=0을 주어서 없앨 수도 있습니다.
em
em단위는 em단위가 있는 곳의 폰트사이즈의 배수입니다. 가령 위의 예시에서 h1의 폰트 속성값이 1.5em, h2의 폰트 속성값이 1.2em, p의 폰트 속성값이 1em이라면, h1의 폰트사이즈는 1.5*16px=24px이고, h2의 폰트사이즈는 1.2*16px=19.2px이며, p의 폰트사이즈는 16px이 되는 것입니다. p의 width가 가령 20em이라면, 20*16px=320px이 됩니다. em은 기준이 되는 값만 수정을 하면 나머지는 비율대로 조정을 해줄 수 있기 때문에 가장 유용한 단위라고 생각합니다. 앞으로 저도 작업을 할 때, 가급적 em단위를 쓰는 습관을 기르려고 합니다.
rem
rem단위는 문서의 기본값의 배수입니다. em과 비슷하지만 em단위는 em단위가 쓰여진 곳(부모 태그)의 기준값에 따라 달라지지만, rem단위는 문서 전체의 기본값의 배수이므로, 문서 전체의 기준값에 따라 달라집니다. 만약, 문서 전체의 기준값을 바꿔야 한다면, style에 :root{font-size:16px} 의 코드를 달아주시면 됩니다. root는 뿌리, 근간이기 때문에 저런 표현을 쓰나봅니다. rem의 r도 root의 약자입니다. 사이트 전체적으로 font-size를 조정해야 한다면 root의 속성값을 변경해주면 됩니다.
Flex(플렉스)는 Flexible Box, Flexbox라고 부르기도 합니다. Flex는 레이아웃 배치 전용 기능으로 고안되었습니다. 그래서 레이아웃을 만들 때 딱히 사용할게 없어서 쓰던 float나 inline-block 등을 이용한 기존 방식보다 훨씬 강력하고 편리한 기능들이 많아요. 출처 :https://studiomeal.com/archives/197
css 전처리기/ 후처리기
전처리기 : 화면에 보여주기 전에 (렌더링 전에) CSS를 변경해서, 스타일을 보여준다. 사용자가 작성하기 쉬운 코드로 작성 => 기본 CSS로 변환 => 렌더링 후처리기 : 화면에 보여주고 나서, CSS 변경 기본 CSS파일 작성 => 렌더링 => 외부 프로그램 사용해서 스타일 변경
전처리기 : Scss, Stylus, Less 후처리기 : PostCSS
버전관리툴 git /svn
형상관리(Version Control Revision Control)툴
소프트웨어 버전 관리 툴이라고도 한다.
형상관리는 소스의 변화를 끊임없이 관리하는 것을 말한다.
소스를 버전 별로 관리할 수 있어서 개발할 때 실수로 소스를 삭제하거나, 수정하기 이전으로 돌아가야되는 경우 유용하게 사용되는 툴.
또한 팀 프로젝트에서도 누가 무엇을 어떻게 수정했는지도 알 수 있기 때문에 코드를 병합하거나 수정된 소스를 추적하는 데에도 쓰인다.
SVN vs GIT 비교
0.3.1 SVN
SVN은 보통 대부분의 기능을 완성해놓고 소스를 중앙 저장소에 commit
commit의 이미 자체가 중앙 저장소에 해당 기능을 공개한다는 의미.
(GIT 과 가장 큰 차이점) 개발자가 자신만의 version history를 가질 수 없다. (그렇기 때문에 local History를 이용하긴 하지만, 일시적이다. 내가 몇일전 까지에 한하여 작업했던 내역을 확인 가능하지만 버전 관리가 되진 않는다.)
commit한 내용에 실수가 있을 시에 다른 개발자에게 바로 영향을 미치게 되는 단점도 있다.
0.3.2 GIT
(GIT 과 가장 큰 차이점) 반면, git은 개발자가 자신만의 commit history를 가질 수 있고, 개발자와 서버의 저장소는 독립적으로 관리가 가능.
commit한 내용에 실수가 있더라도 이 바로 서버에 영향을 미치지 않는다
개발자는 마음대로 commit(push)하다가 자신이 원하는 순간에 서버에 변경 내역(commit history)을 보낼 수 있으며, 서버의 통합 관리자는 관리자가 원하는 순간에 각 개발자의 commit history를 가져올 수 있음.
이렇게 git은 서버 저장소와 개발자 저장소가 독립적으로 commit history를 가져갈 수 있기 때문에 매우 유연한 방식으로 소스를 운영할 수 있으며, 이러한 유연성이 git의 가장 큰 장점이다.
es5, es6 문법 차이
레거시 코드가 프로젝트에 존재할수있기때문에
1.let,const keyword 2.Arrow function 3.for/of 4.Class 5.Promise 6.Symbol 7.Default parameter 8.function rest parameter 9.String.inclues()/.startsWith()/.endsWith() 10.Array.from()/.keys()/.find()/.findIndex() 11.New Math Methods 12.New Number Properties, Methods 13.New Global Methods 14.Iterable Object.entries 15.Javascript Module
gulp
Gulp는 Node.js 기반의 프로세스 자동화 도구이며 MIT 라이센스의 오픈소스 프로젝트입니다. 회사 일을 하면서 스크립트를 난독화하거나 파일을 복사하는 등의 작업이 반복될 때가 많았는데, Gulp는 이런 반복되는 작업들을 자동화하기 위해 개발된 도구입니다. 또한 Gulp의 플러그인을 사용하면 기능을 다양하게 확장할 수도 있습니다.
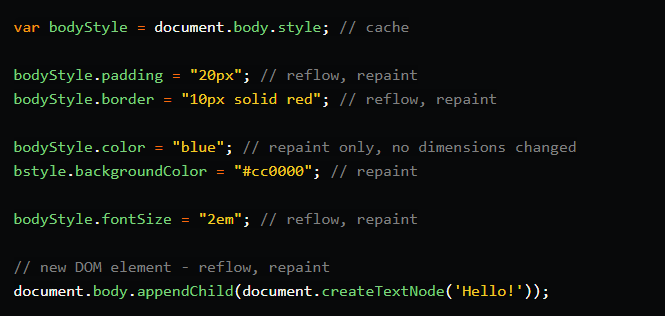
- DOM 요소의 위치 변경, 크기 변경 (margin, padding, border, width, height, 등..)
- display : none으로 DOM 요소를 숨기는 경우
- DOM 노드를 이동하거나 애니메이션을 생성하는 경우
- 창 크기를 조정하는 경우 (Resizing)- 글꼴 스타일을 변경하는 경우 (요소의 geometry가 변경되고 이는 페이지에 있는 다른 요소의 위치나 크기에 영향을 미칠 수 있고 두 요소 모두 브라우저에서 reflow를 수행하고 repaint 과정을 거침)- 스타일 시트를 추가하거나 제거하는 경우- DOM을 조작하는 스크립트를 수정하는 경우
- offset, scrollTop, scrollLeft와 같은 계산된 스타일 정보 요청
- 이미지 크기 변경
Repaint만 일어나는 경우
- visibility : hidden 으로 DOM 요소를 숨기는 경우 (레이아웃이나 위치 변경이 없어 repaint만 발생)
- background-color, visibillty, outline 등의 스타일 변경
Reapint와 Reflow 최소화하는 방법
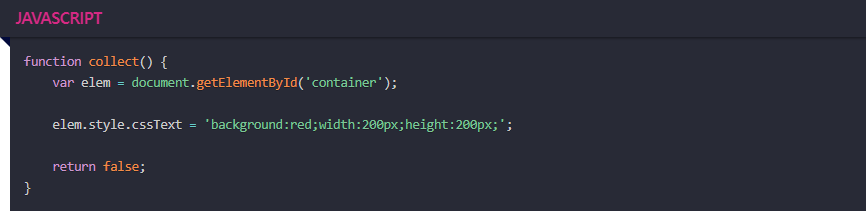
1) 개별 스타일을 바꾸기보다 클래스 이름을 변경. 동적인 스타일인 경우 cssText속성을 편집한다.
[출처]https://webclub.tistory.com/346
2) DOM 변경사항을 일괄처리
- documentFragment를 사용하여 DOM사용을 최소화한다. ( documentFragment는 DOM에 적용되기 전까지는 메모리상에만 존재)
:<table>은 점진적으로 렌더링 되지 않고 모두 로드되고 테이블 너비가 계산된 후 화면에 그려진다. 콘텐츠의 값에 따라 테이블 너비가 계산되기 때문에, 테이블 콘텐츠의 작은 변경만 있어도 테이블 너비가 다시 계산되고 테이블의 모든 노드들이 Reflow가 발생. 데이터 표시용 도로 사용 시 table-layout:fixed를 사용하자.
타이머에서 실행되게 하면 추가적인 실행 사이클이 발생하게 되는데, 첫 번째 요소에 대한 작업이 한 사이클 내에서 실행되고, 타이머의 실행은 먼저 실행된 사이클이 끝난 다음에 진행된다. 이로 인해 결과적으로 리플로와 리페인트가 두 번 일어나게 되므로 리플로우와 리페인트가 일어날 수 있는 작업은 가능하면 실행 사이클 안에서 실행하도록 처리하는 편이 효과적이다.
7) 노드복제
: 변경하려는 요소의 노드를 복제한 후 복제된 노드에 필요한 작업을 실행하는 방법. 복제된 노드는 DOM 트리에 추가된 상태가 아니므로 렌더링 성능에 영향을 줄 수 있는 작업을 실행하더라도 리플로나 리페인트가 발생하지 않는다.
작업이 모두 완료된 이후 복제된 노드를 원래 노드와 치환해 DOM 트리에 변경된 사항이 적용되게하면 치환 시점에만 리플로와 리페인트가 발생한다.
var element = document.getElementById("box1");
var clone = element.cloneNode(true); // 원본 노드를 복제한다.
for(var i=0; i < 100; i++) {
clone.style.width = i + "px";
}
// 변경된 복제 노드를 DOM 트리에 반영하기 위해 기존 노드와 치환한다.
parentNode.replaceChild(clone, element);
이렇게 만들어진 DOM와 CSSOM은 렌더링(브라우저에 시각적으로 출력하는 것)을 위해 렌더 트리로 결합된다.
만약 script 태그를 만나면, css와 동일하게 JS코드를 실행하기 위해 파싱을 중단한다.
이후 JS엔진을 실행하고 JS코드를 파싱한다.
자바스크립트가 DOM, CSSOM을 변경하는 경우리렌더링을 하게 된다. 리플로우: 레이아웃 계산을 다시 하는 것 리페인트: 재결합된 렌더 트리를 기반으로 다시 페인트를 하는 것
여기서 script태그를 만날때마다 파싱이 중단되는 문제를 script 태그 뒤에 async 혹은 defer를 붙여줌으로써 해결할 수 있다. async: HTML 파싱, JS 파일 로드가 동시에 진행 defer: DOM 생성이 완료된 직후, JS의 파싱과 실행이 진행된다.